

This package implements the tools for the goodness-of-fit analysis for the probit model (Dungang Liu, Xiaorui Zhu, Brandon Greenwell, and Zewei Lin (2022)). This package can generate a point or interval measure of the surrogate \(R^2\). It can also provide a ranking measure of each variable’s contribution in terms of surrogate goodness-of-fit measure. This ranking assessment allows one to check the importance of each variable in terms of their explained variance. It can be jointly used with other existing R packages for variable selection and model diagnostics in the model-building process.
The SurrogateRsq package will be available on SurrogateRsq
CRAN soon.
SurrogateRsq development version from GitHub
(recommended)# Install the development version from GitHub
if (!requireNamespace("devtools")) install.packages("devtools")
devtools::install_github("XiaoruiZhu/SurrogateRsq")SurrogateRsq from the CRAN# Install from CRAN
install.packages("SurrogateRsq")The following example shows the R code for analyzing white wine-tasting data ( data(“WhiteWine”) ).The tasting dataset of white wine contains 4898 samples and 11 explanatory variables. The explanatory variables are the physicochemical features of the wine, for example, the acidity, sugar, dioxide, pH, and others. The response variable is the tasting rating score of the wine, which ranges from 0 (very bad) to 10 (excellent).
library(SurrogateRsq)
library(MASS)
data("WhiteWine")
# Build the full model
full_formula_white <-
as.formula(quality ~ fixed.acidity + volatile.acidity + citric.acid +
residual.sugar + chlorides + free.sulfur.dioxide +
total.sulfur.dioxide + density + pH + sulphates +
alcohol)
naive_model_white <- polr(formula = full_formula_white,
data = WhiteWine,
method = "probit")
# selected model
select_model_white <-
update(naive_model_white,
formula. =
". ~ . - citric.acid - chlorides - total.sulfur.dioxide - density")
# surrogate R-squared
surr_obj_white <-
surr_rsq(model = select_model_white,
full_model = select_model_white,
avg.num = 30)
print(surr_obj_white$surr_rsq,
digits = 3)
# surrogate R-squared rank table
Rank_table_white <-
surr_rsq_rank(object = surr_obj_white,
avg.num = 30)
print(Rank_table_white, digits = 3)
# 95% confidence interval surrogate R-squared
surr_obj_white_ci <- surr_rsq_ci(surr_rsq = surr_obj_white,
alpha = 0.05,
B = 2000)In empirical studies, goodness-of-fit analysis should be used jointly with other statistical tools, such as variable screening/selection and model diagnostics, in the model-building and refining process. In this section, we discuss how to follow the workflow in the following diagram to carry out statistical modeling for categorical data. We also discuss how to use the () package with other existing R packages to implement this workflow. As Liu et al. (2023)’s method requires a full model, researchers and practitioners can also follow the process in Figure to initiate a full model so as to facilitate goodness-of-fit analysis.
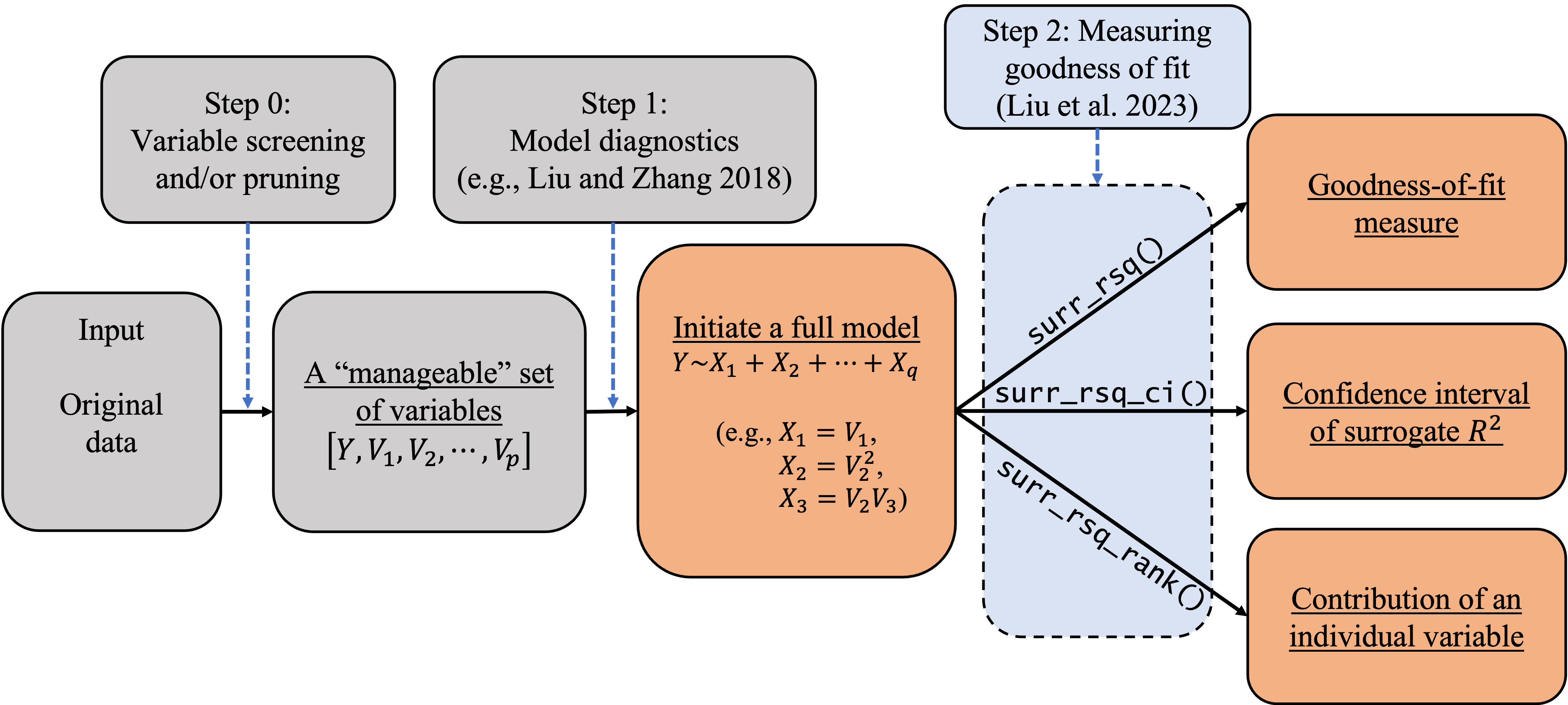
In (), we can use the AIC/BIC/LASSO or any other variable selection methods deemed appropriate to trim or prune the set of explanatory variables to a ``manageable’’ size (e.g., less than 20). The goal is to eliminate irrelevant variables so that researchers can better investigate the model structure and assessment. The variable selection techniques have been studied extensively in the literature. Specifically, one can implement (i) the best subset selection using the function () in the () package; (ii) the forward/backward/stepwise selection using the function () in the R core; (iii) the shrinkage methods including the (adaptive) LASSO in the package; (iv) the regularized ordinal regression model with an elastic net penalty in the package; and (v) the penalized regression models with minimax concave penalty (MCP) or smoothly clipped absolute deviation (SCAD) penalty in the package. When the dimension is ultrahigh, the sure independence screening method can be applied through the package. When the variables are grouped, one can apply the group selection methods including the group lasso, group MCP, and group SCAD through the package. In some cases, () may be skipped if the experiment only involves a (small) set of controlled variables. In these cases, the controlled variables should be modeled regardless of statistical significance or predictive power. We limit our discussion here because our focus is on goodness-of-fit analysis.
In (), we can use diagnostic tools to inspect the model passed from (), adjust its functional form, and add additional elements if needed (e.g., higher-order or interaction terms). For categorical data, we can use the function () in the package to generate three types of diagnostic plots: residual Q-Q plot, residual-vs-covariate plot, and residual-vs-fitted plots. These plots can be used to visualize the discrepancy between the working model and the ``true’’ model. Similar plots can be produced using the function () in the package. These diagnostic plots give practitioners insights on how to refine the model by possibly transforming the regression form or adding higher-order terms. At the end of this diagnosing and refining process, we expect to have a ((_{full})) for subsequent inferences including goodness-of-fit analysis.
In (), we can use the functions developed in our package to examine the goodness of fit of the full model (_{full}) and various reduced models of interest. Specifically, we can produce the point and interval estimates of the surrogate (R^2) by using the functions () and (). In addition, we can quantify the contribution of each individual variable to the overall surrogate (R^2) by using the function (). Based on the percentage contribution, the function () also provides ranks of the explanatory variables to show their relative importance. In the following section, we will show in a case study how our package can help us understand the relative importance of explanatory variables and compare the results across different samples. The ``comparability’’ across different samples and/or models is an appealing feature of the surrogate (R^2), which will be discussed in detail along with the R implementation.
# Load packages
library(SurrogateRsq)
library(MASS)
# Load data and preparation
data("RedWine")
data("WhiteWine")
### We remove an outlier where total.sulfur.dioxide>200.
RedWine2 <- subset(RedWine, total.sulfur.dioxide <= 200)full_formula <-
as.formula(quality ~ fixed.acidity + volatile.acidity + citric.acid +
residual.sugar + chlorides + free.sulfur.dioxide +
total.sulfur.dioxide + density + pH + sulphates +
alcohol)
naive_model <- polr(formula = full_formula,
data = RedWine2,
method = "probit")
summary(naive_model)
# Use exhuastive search for searching the best model
fullmodel <- polr(quality ~ ., data = RedWine2, method = "probit")
model_exhau <- leaps::regsubsets(x = quality ~ .,
data = RedWine2,
nbest = 2,
nvmax = 11)
plot(model_exhau)
select_model <-
update(naive_model,
formula. =
". ~ . - fixed.acidity - citric.acid - residual.sugar - density")
# Conduct model diagnostics by following the workflow
library(PAsso)
p_sulphates <-
diagnostic.plot(object = select_model,
output = "covariate",
x = RedWine2$sulphates,
xlab = "(a)")
mod_add_square <-
update(select_model, formula. = ". ~ . + I(sulphates^2)")
p_sulphates2 <-
diagnostic.plot(object = mod_add_square,
output = "covariate",
x = RedWine2$sulphates,
xlab = "(b)")
mod_full <-
update(mod_add_square, formula. = ". ~ . + I(sulphates^3)")
p_sulphates3 <-
diagnostic.plot(object = mod_full,
output = "covariate",
x = RedWine2$sulphates,
xlab = "(c)")
gridExtra::grid.arrange(p_sulphates, p_sulphates2, p_sulphates3, ncol = 3)
# Compare models
library(stargazer)
stargazer(naive_model, select_model, mod_add_square, mod_full,
column.labels = c("Naive", "Selected", "+ sulphates-squared", "+ sulphates-cubic"),
order = c("fixed.acidity", "volatile.acidity", "citric.acid",
"residual.sugar", "chlorides", "free.sulfur.dioxide",
"total.sulfur.dioxide", "density", "pH",
"sulphates", "I(sulphates-sqr)", "I(sulphates-cubic)",
"alcohol"),
type = "text")library(SurrogateRsq)
set.seed(777)
surr_obj_mod_full <-
surr_rsq(model = mod_full,
full_model = mod_full,
avg.num = 30)
print(surr_obj_mod_full$surr_rsq,
digits = 3)
# Surrogate R-squared of a smaller model (select_model)
surr_obj_lm <- surr_rsq(model = select_model,
full_model = mod_full,
avg.num = 30)
print(surr_obj_lm$surr_rsq,
digit = 3)
# Construct the confidence interval
full_mod_rsq_ci <-
surr_rsq_ci(surr_rsq = surr_obj_mod_full,
alpha = 0.05,
B = 2000)
full_mod_rsq_ci
# Creat the importance ranking table
set.seed(777)
# Importance ranking table of the full model
Rank_table_mod_full <-
surr_rsq_rank(object = surr_obj_mod_full,
avg.num = 30)
print(Rank_table_mod_full, digits = 3)
# Importance ranking table of two groups of variables
var_set <- list(c("sulphates", "I(sulphates^2)", "I(sulphates^3)"),
c("I(sulphates^2)", "I(sulphates^3)"))
Rank_table2 <-
surr_rsq_rank(object = surr_obj_mod_full,
var.set = var_set,
avg.num = 30)
print(Rank_table2, digits = 3)